 09039151075
09039151075

داده کاوی و تحلیل رفتار مشتریان, همه مقالات آموزشی
آمادهسازی دادهها در اجرای پروژههای دادهکاوی

فروردین
آمادهسازی دادهها در اجرای پروژههای دادهکاوی
آمادهسازی دادهها مرحلهای مهم در اجرای پروژههای دادهکاوی است.
در این پست قصد داریم به موضوع « آمادهسازی دادهها » بپردازیم. در مرحله آمادهسازی دادهها، مجموعه عملیاتی انجام میشود که باعث برطرف شدن مشکلات مختلف دادههای مورداستفاده خواهد شد.
ازجمله عملیات آمادهسازی داده میتوان به پاکسازی داده و انجام برخی از پیشپردازشهای لازم بر روی مجموعه دادهها اشاره کرد. پاکسازی دادهها شامل تشخیص و حذف نقاط دورافتاده، مدیریت داده های از دست رفته و حذف رکوردهای تکراری است.
از جمله پیش پردازش دادهها شامل یکپارچهسازی، تجمیع، انتخاب زیرمجموعهای از ویژگیها، نمونهگیری، گسستهسازی، نرمالسازی دادهها و… است.
مرحله آمادهسازی دادهها یکی از مهمترین مراحل انجام یک پروژه دادهکاوی است که بههیچعنوان نباید نادیده گرفته شود. این مرحله کمی زمانبر است و طی آن دادهها را برای مدلسازی آماده میکنیم.
همچنین باید به این نکته توجه داشت که چنانچه مدلهای دادهکاوی بر اساس دادههای پاکسازی نشده و ناقص بهدستآمده باشند، غیرقابلاعتماد خواهند بود و طبیعتاً الگوهای رفتاری مشتریان نیز بهدرستی قابلتشخیص نخواهند بود.
[box type=”success” align=”aligncenter” class=”” width=””]دادههای پاکسازی نشده سالانه هزینههای زیادی را به سازمانها تحمیل میکنند.[/box]

• بیایید با هم برخی از ویژگیهای دادههای کثیف یا پاکسازی نشده را بررسی کنیم.همچنین برای هر یک از مراحل پاکسازی راهنمای اجرا در نرم افزار RapidMiner و زبان R نیز برای شما ارائه نمودیم.
۱- کامل نبودن داده ها
دادهها ممکن است که در زمان جمع آوری گم شده باشند. به این داده ها از دست رفته می گوییم.
در واقع داده از دست رفته به مقادیری از رکوردهای مجموعه داده گفته میشود که اطلاعات آن به دلایل مختلف از دست رفته یا در اختیار ما قرار نگرفته است.
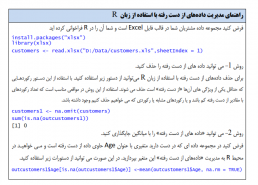
در شکل زیر بخشی از یک مجموعه داده را مشاهده میکنید که به برخی از مقادیر مربوط به متغیر شغل مشتریان دسترسی نداریم. به این مقادیر داده از دست رفته می گویند.
ما قرار است که با استفاده از تحلیل داده های مشتریان به سوالات کسب و کار پاسخ دهیم و از نتایج تحلیل ها در تصمیمگیری های مدیریتی استفاده کنیم. دادههای ناقص و از دست رفته در بسیاری از موارد باعث ایجاد مشکل در تحلیل داده ها می شود. بسیاری از الگوریتم ها با وجود داده های از دست رفته قابلیت اجرا ندارند.
بنابراین در مرحله پاکسازی داده ها باید به فکر مدیریت داده های از دست رفته باشید. روش های مختلفی برای این کار وجود دارد. در ادامه به برخی از آن ها اشاره می کنیم.
- حذف کردن: در این روش رکوردهایی که حداقل یکی از ویژگیهای آنها «از دست رفته» است حذف می شوند. استفاده از این روش در مواقعی مناسب است که تعداد رکوردهای با مقادیر از دست رفته کم باشد و یا رکوردهای مشابه یا رکوردی که می خواهیم حذف کنیم وجود داشته باشد.
- جایگزین کردن: در این روش مقادیر «از دست رفته» با تمام مقادیر امکانپذیر (به عنوان نمونه میانگین، میانه، ماکزیمم، مینیمم و … ) جایگزین میشود.
- تخمین زدن: در این روش مقادیر «از دست رفته» با استفاده از روش های ابتکاری و با استفاده از الگوریتمهای ردهبندی پیشبینی می شود.

۲- وجود دادههای پرت
دادههای پرت با عنوان دادههای دورافتاده (Outlier) نیز شناخته می شوند. رکوردهایی هستند که مقادیر ویژگیهای آنها نسبت به سایر رکوردها بسیار متفاوت است. این تفاوت باعث میشود که در فضای چندبعدی ویژگیها، محل قرار گرفتن دادههای پرت نسبت به سایر رکوردها بسیار متفاوت باشد. در شکل زیر نمونه ای از داده های دورافتاده نشان داده شده است.
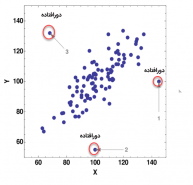
نمونه ای از داده های دورافتاده (پرت)
برای مثال ممکن است در بین مشتریان شما افرادی باشند که خریدهای بزرگی را انجام داده باشند. اما این افراد واسطههایی باشند که اقلام را خریداری و بیرون از فروشگاه شما به فروش میرسانند و با مشتریان اصلی شما فرق داشته باشند. شما باید این مشتریان را شناسایی کنید.
همچنین ممکن است دادههای پرت به علت خطا در ورود دادهها، گزارشدهی اشتباه و خطاهای نمونهگیری رخ داده باشد. توجه کنید که وجود دادههای اشتباه باعث ایجاد نتایج غیرقابل اطمینان می گردد. بنابراین شناسایی دادههای پرت که به علت خطا در ورود داده ها ایجاد شده اند اهمیت زیادی در کیفیت مدلسازی و تحلیل داده ها و اعتبار نتایج دارا می باشد. در این گونه موارد با اصلاح و یا حذف دادههای پرت، میتوان کیفیت دادههای ورودی به الگوریتمهای مدلسازی را ارتقاء داد.
روش های مختلفی برای تشخیص نقاط دورافتاده وجود دارد در ادامه به برخی از آن ها اشاره می کنیم.
- استفاده از ابزارهای مصورسازی
استفاده از ابزارهای مصورسازی همچون نمودار پراکنش، هیستوگرام، نمودار جعبهای و …. یکی از روشهای تشخیص نقاط دادههای دورافتاده است.
- استفاده از نمودار کنترل شوهارت
نمودار کنترل شوهارت از نظر آماری دارای یک خط مرجع CL (Central Line ) و دو خط حدود معین، یکی حد کنترل بالایی UCL (Upper Control Limit ) و دیگری حد کنترل پایینی LCL (Lower Control Limit ) است. هر رکوردی که از حدود بالا و پایین خارج شده باشد، به عنوان نقطه دورافتاده در نظر گرفته میشود.
در شکل زیر مثالی از تشخیص نقطه دورافتاده با استفاده از نمودار شوهارت ارائه شده است.
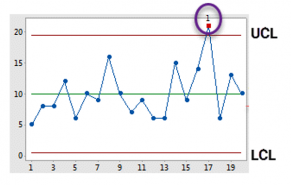
تشخیص نقاط دورافتاده با استفاده از روش شوهار

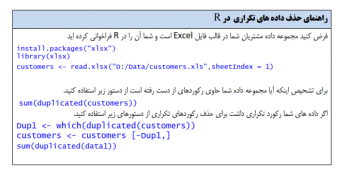
۳- وجود دادههای تکراری

دادههای کثیف شامل داده های تکراری هستند. ممکن است اطلاعات برخی از مشتریان شما بیش از یکبار وارد شده باشد. شما باید تمامی رکوردهای تکراری موجود در مجموعه داده را شناسایی و حذف کنید. وجود رکوردهای تکراری ممکن است موجب هدف گذاری مجدد یک مشتری شود و هزینه اضافی بر سازمان متحمل گردد.

در بالا در خصوص آماده سازی داده ها صحبت کردیم. گفتیم که مرحله آمادهسازی دادهها، شامل مجموعه عملیاتی است که باعث برطرف شدن مشکلات مختلف دادههای مورداستفاده خواهد شد.
ازجمله عملیات آمادهسازی داده میتوان به پاکسازی داده و انجام برخی از پیشپردازشهای لازم بر روی مجموعه دادهها اشاره کرد. پاکسازی دادهها شامل تشخیص و حذف نقاط دورافتاده، مدیریت داده های از دست رفته و حذف رکوردهای تکراری است.
از جمله پیش پردازش دادهها شامل یکپارچهسازی، تجمیع، انتخاب زیرمجموعهای از ویژگیها، نمونهگیری، گسستهسازی، نرمالسازی دادهها و … است.
در ادامه در مورد روش های پاکسازی داده ها توضیحاتی را ارائه نمودیم و همچنین برای هر یک از مراحل پاکسازی راهنمای اجرا در نرم افزار RapidMiner و زبان R نیز برای شما ارائه نمودیم.
قصد داریم که به ارائه توضیحاتی در خصوص برخی از پیش پردازش های لازم در مرحله آمادهسازی دادهها بپردازیم. در این پست نیز راهنمای نرم افزار RapidMiner و زبان R برای شما ارائه شده است.
۱-یکپارچهسازی دادهها
ممکن است دادههایی که از مشتریان در اختیارداریم در جداول جداگانهای قرار داشته باشند و همهی دادهها در یک جدول نباشند. در این صورت میبایست دادههای مشتریان خود را جمعآوری کنید و آنها را در قالب یک جدول واحد، یکپارچه نمایید. چنانچه دادههای مشتریان خود را یکپارچه نکنید احتمالاً اطلاعات ارزشمند زیادی را از دست خواهید داد.
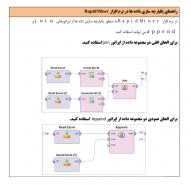

۲-نمونهگیری از دادهها
یکی دیگر از مراحل پیشپردازش دادهها، نمونهگیری است. گاهی اوقات تحلیل و پردازش کل مجموعه داده برای الگوریتمهای دادهکاوی بسیار زمانبر است؛ از این رو تحلیلگران داده از نمونهگیری استفاده میکنند. در نمونهگیری از میان تمام رکوردهایی که در مجموعه داده وجود دارند، تعدادی از رکوردها با توجه به اندازه نمونه انتخاب خواهند شد. نمونهگیری به تحلیلگران داده کمک میکند تا پردازش و تحلیل دادهها را با سرعت بیشتری انجام دهند. باید توجه داشت که نمونهگیری در صورتی قابل قبول است که کیفیت دانش استخراج شده را کاهش ندهد.

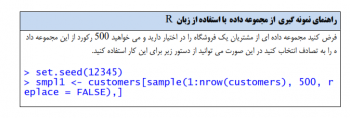
۳-کاهش بُعد
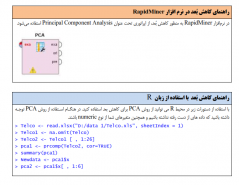
مدلهای کاهش ابعاد، کاهش مؤثر ابعاد دادهها و حذف اطلاعات اضافی را هدف قرار میدهد. تحلیل مؤلفههای اصلی (Principle Components Analysis) از جمله الگوریتمهای رایج کاهش دادهها است. PCA روشی آماری است که به منظور کاهش بُعد به کار میرود. این روش همبستگی بین فیلدهای ورودی را محاسبه میکند و مجموعهای از مؤلفههای اصلی ارائه میدهد که امکان «کاهش داده» را بدون از دست دادن حجم بالایی از اطلاعات مربوط به ورودی اصلی به گونهای اثربخش فراهم میآورد.
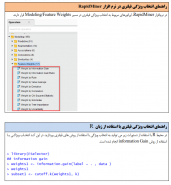
۴-انتخاب زیرمجموعهای از ویژگیها
یکی از مهمترین عملیات پیشپردازش دادهها، انتخاب زیرمجموعهای از ویژگیها است. در این روش ویژگیهایی که افزونه و غیر مرتبط هستند حذف خواهند شد. ویژگیهای افزونه ویژگیهایی هستند که با توجه به سایر ویژگیها قابل محاسبه بوده و ویژگیهای غیر مرتبط نیز ویژگیهایی هستند که هیچ ارزش اطلاعاتی برای مسئله نداشته باشند.
در دادهکاوی روشهای مختلفی برای انتخاب زیرمجموعهای از ویژگیها وجود دارد. از معروفترین روشهای انتخاب ویژگی میتوان به روشهای فیلتری اشاره نمود. روشهای فیلتری به هر یک از ویژگیهای (متغیرهای) پیشبینی کننده، وزنی را اختصاص میدهند.
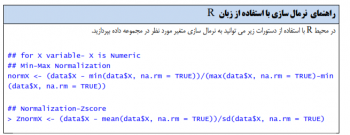
۵-نرمال سازی
ممکن است یک تحلیلگر داده با موقعیتهایی مواجه گردد که ویژگیهای در دسترس شامل مقادیری با محدوده یا دامنه متفاوت باشند. برای مثال فرض کنید که در مجموعه دادهای دو ویژگی سن و درآمد مشتریان در دسترس هستند. سن مشتریان در بازه ۱۸ تا ۶۰ سال است و درآمد آنها در بازه ۲۰۰۰۰۰۰ تومان تا ۲۰۰۰۰۰۰۰ تومان است. بنابراین این دو ویژگی دارای دامنههای بسیار متفاوتی هستند. در این حالت ممکن است ویژگیهای با مقادیر بزرگ اثر بیشتری نسبت به ویژگیهای با مقادیر کم داشته باشند. این مشکل با نرمالسازی ویژگیها بهنحویکه مقادیرشان در دامنههای مشابه قرار گیرند برطرف خواهد شد.


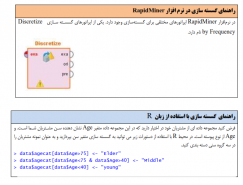
۶- گسسته سازی

در گسسته سازی دادهها هدف این است که نوع ویژگیهای پیوسته بازهای و نرخی به نوع اسمی تبدیل شوند. دلیل این کار این است که گاهی از اوقات ویژگیهای پیوسته دارای مقادیر بسیار بزرگی هستند که ساخت مدل را پیچیده میسازد. همچنین بسیاری از الگوریتمهای دادهکاوی تنها در فضای گسسته از ویژگیها اجرا میشوند و وجود ویژگیهای پیوسته مانع اجرای این الگوریتمها میشوند.
[box type=”shadow” align=”aligncenter” class=”” width=””]اگر تمایل دارید با جزئیات مراحل پیش پردازش داده ها در نرم افزار رپیدماینر آشنا شوید به شما پیشنهاد می کنیم که کتاب «تُندآموز RapidMiner» را مطالعه کنید.
امتیاز شما به این نوشته: